Tối ưu token trong Claude Projects
Tuần này tôi ngồi dọn lại mấy project trong Claude, và nhận ra mình hơi bị ngây thơ suốt mấy tháng trời..
Kiểu “cứ quăng file vào cho nó nhiều là ngon” thì ra hổng phải vậy.
Nên viết bài này chia sẻ lại những gì tôi vừa tìm hiểu được, dành cho anh chị em dân không chuyên nhưng muốn hiểu cách Claude Projects thực sự hoạt động.
Đầu tiên — Token là gì?
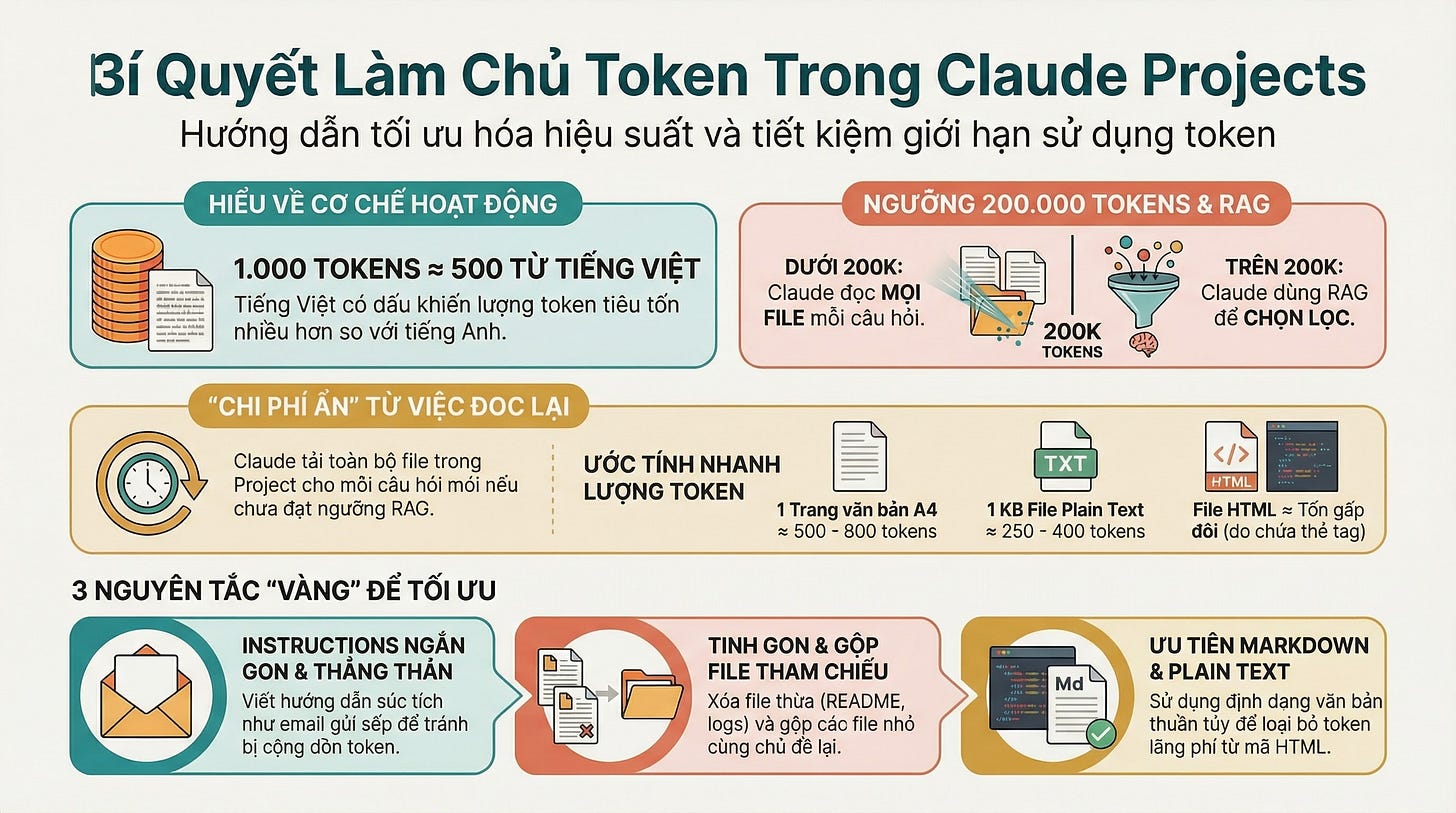
Token là đơn vị nhỏ nhất mà Claude dùng để “đọc” và “xử lý” text.
Một số quy đổi nhanh:
1,000 tokens ≈ 750 từ tiếng Anh
1,000 tokens ≈ 500 từ tiếng Việt (do tiếng Việt có dấu, phức tạp hơn)
200,000 tokens ≈ 500 trang sách
Tại sao cần quan tâm? Vì Claude có giới hạn cửa sổ ngữ cảnh (context window) — tức là bộ nhớ làm việc của nó. Mọi thứ mình gửi vào + mọi thứ Claude trả lời = phải nằm gọn trong cửa sổ này.
Vượt quá thì Claude bắt đầu.. quên, ngáo luôn.
Điều tôi hiểu sai suốt mấy tháng
Tôi cứ nghĩ Claude Projects hoạt động kiểu “thông minh” là.. load file nào cần thì load, không cần thì bỏ qua.
Thì ra.. trật lất hết (SAI).
Anthropic documentation nói rõ:
Khi tổng project knowledge DƯỚI context limit (~200k tokens):
→ Claude load TOÀN BỘ files vào context MỖI câu hỏi. Không selective gì hết.
Khi tổng project knowledge TRÊN context limit:
→ Tự động chuyển sang RAG mode, lúc này mới search selective, chỉ load chunks liên quan.
Nôm na là: Nếu project của bạn có 10 files nhỏ tổng 20,000 tokens, thì mỗi lần hỏi Claude, cả 10 files được load vào. Dù bạn chỉ hỏi về 1 file.
Đây là “chi phí ẩn” mà nhiều người hổng biết.
Ví dụ thực tế từ project tôi vừa dọn
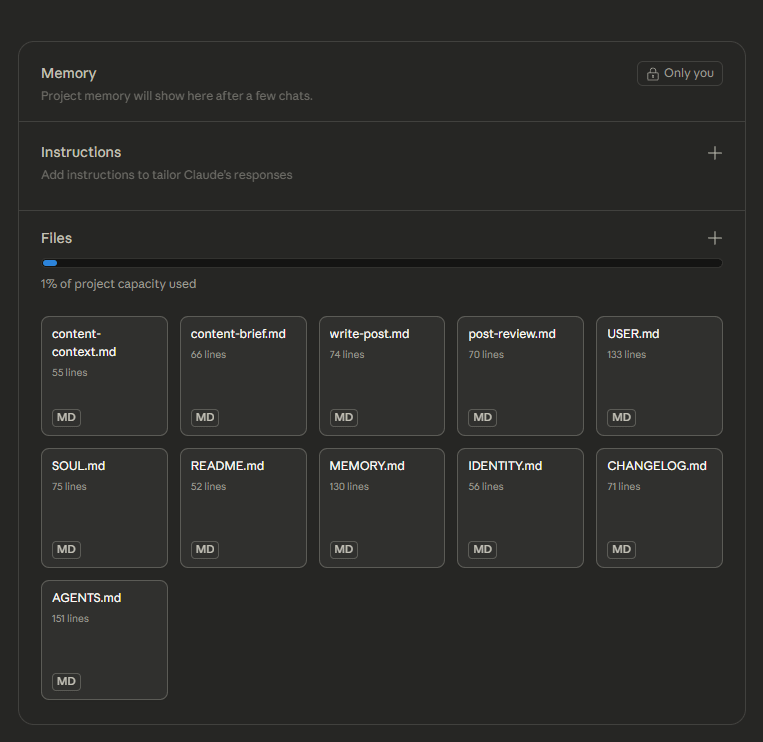
Trước khi tối ưu:
11 files trong project
Instructions dài (~3,000 tokens)
Tổng project knowledge: ~20,000 tokens
—> Mỗi câu hỏi: Instructions + 11 files + conversation = ~25,000 tokens input
Sau khi tối ưu:
Gộp còn 2 files chính (bỏ README, CHANGELOG, file trùng lặp)
Instructions gọn lại (~2,000 tokens)
Tổng project knowledge: ~8,000 tokens
—> Mỗi câu hỏi: Instructions + 2 files + conversation = ~10,000 tokens input
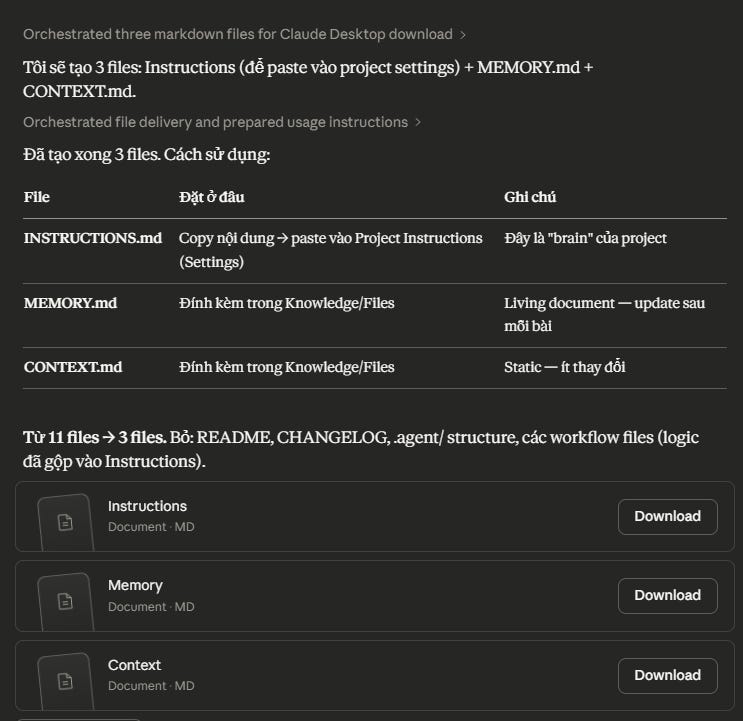
Tiết kiệm: ~15,000 tokens/câu hỏi.
Nghe có vẻ không nhiều, nhưng nhân với 50 câu hỏi/ngày, nhân với 30 ngày.. con số bắt đầu đáng kể.
Và quan trọng hơn:
Claude focus tốt hơn khi context gọn.
Ít noise = trả lời chính xác hơn.
4 nguyên tắc tối ưu token cho người không chuyên
1. Instructions — giữ ngắn, không lặp
Instructions được inject vào context MỖI câu hỏi. Chiếm token cố định.
Nếu instruction dài 5,000 tokens, mỗi câu hỏi bạn đã “tốn” 5,000 tokens trước khi nói gì.
Tip:
Viết instructions như viết email cho sếp bận — ngắn gọn, rõ ràng, đi thẳng vào việc.
2. Dọn file không cần thiết
README.md? CHANGELOG? File “lưu lại cho chắc”?
Nếu Claude không cần reference mỗi ngày → bỏ luôn đi.
Thật ra mấy cái này phù hợp project dưới máy tính xài trên Antigravity/Claude Code/Windsurf/Cursor thôi, còn Claude Desktop/Web thì không cần.
3. Gộp file có nội dung liên quan
Thay vì 5 file nhỏ về cùng một chủ đề → gộp thành 1 file thôi.
Giảm trùng lặp.
4. Chú ý format file
HTML files thường chiếm nhiều token hơn do Claude đọc cả tags. Markdown hoặc plain text gọn hơn.
(số liệu từ một bài test tôi đọc: cùng nội dung, HTML chiếm gấp đôi token so với Markdown —> à.. cái này để tôi lên bài liên quan HTML to Markdown sau)
Làm sao biết project đang dùng bao nhiêu token?
Hiện tại Claude.ai chưa có dashboard hiển thị token usage chi tiết. Nhưng có vài cách ước tính:
Cách 1: Dùng tool online
Tôi hay dùng tool count token miễn phí này:
- claudetokenizer.com — support Claude models mới nhất, upload được file
Copy text vào, nó trả về số token.
Cách 2: Xem dấu hiệu RAG
Nếu project của bạn đã chuyển sang RAG mode, Claude sẽ hiện “Indexing” indicator trong giao diện. Lúc đó bạn biết mình đã vượt ngưỡng ~200k tokens.
Cách 3: Ước tính nhanh
Tính nhẩm đại đại:
- 1 trang A4 text thường ≈ 500-800 tokens
- 1KB file text ≈ 250-400 tokens (tùy ngôn ngữ)
RAG là gì và khi nào nó kích hoạt?
RAG (Retrieval Augmented Generation) là chế độ “tìm kiếm thông minh” của Claude.
Khi KHÔNG có RAG (project nhỏ):
Claude load toàn bộ files vào “bộ nhớ làm việc” mỗi câu hỏi.
Khi CÓ RAG (project lớn, vượt 200k tokens):
Claude dùng tool search để tìm chunks liên quan, chỉ load những phần cần thiết.
Theo Anthropic:
- RAG tự động kích hoạt khi project tiến gần hoặc vượt context window limit
- Dung lượng project có thể mở rộng lên 10x so với mode thường
- Chất lượng response vẫn tương đương
Một điểm hay: Nếu sau đó bạn xóa bớt files và project về dưới ngưỡng 200k, Claude tự động chuyển ngược về mode load-toàn-bộ.
---
Sẵn tiện nói thêm chuyện bên lề..
Tôi từng nghĩ “càng nhiều context càng tốt” — kiểu cho Claude đọc hết mọi thứ, nó sẽ hiểu mình hơn.
Thật ra ngược lại.
Claude như một nhân viên mới vào công ty. Bạn đưa cho họ 500 trang tài liệu trước buổi họp đầu tiên — họ sẽ lú luôn và hổng biết đâu là quan trọng.
Nhưng nếu bạn đưa 10 trang tóm tắt đúng trọng tâm — họ sẽ vào việc nhanh hơn nhiều.
Context gọn = Claude focus hơn = output tốt hơn.
Đơn giản vậy thôi :3
---
Nguồn tham khảo:
- Anthropic Help Center: RAG for Projects — https://support.claude.com/en/articles/11473015-retrieval-augmented-generation-rag-for-projects
- Anthropic Help Center: Context Window — https://support.claude.com/en/articles/8606394-how-large-is-the-context-window-on-paid-claude-plans
- Anthropic Docs: Token Counting API — https://docs.anthropic.com/en/docs/build-with-claude/token-counting
- Anthropic Docs: Context Windows — https://docs.claude.com/en/docs/build-with-claude/context-windows
Tool count token:
- https://claudetokenizer.com (official API)
- https://lunary.ai/anthropic-tokenizer
- https://token-counter.app/anthropic
#voquoccuong
Bài viết đăng lần đầu trên Substack →


